단단한 심층 강화학습

0. 소주제들
1. MDP와 POMDP
실제 세계에서 거의 대부분의 문제들은 POMDP이다.
1. 강화학습 소개
1.1 MDP로서의 강화학습
- $s_t \in S$: 상태의 집합
- $a_t \in A$: 행동의 집합
- $P(s_{t+1}|s_t,a_t)$: 상태 전이 함수 ← Markov property
- $R(s_t, a_t, s_{t+1}) = r_t$: 보상 함수
- 경로: $\tau = (s_0, a_0, r_0) , … \ ,(s_T, a_T, r_T)$
- 경로 보상 함수: $R(\tau)=r_0 + \gamma r_1 + \cdot \cdot \cdot + \gamma ^Tr_T = \sum_{t=0}^{T}\gamma ^t r_t$
- 목적함수: \(J(\tau) = \mathbb{E}_{\tau \sim \pi}[R(\tau)] = \mathbb{E}_{\tau }[\sum_{t=0}^{T}\gamma ^t r_t]\)
→ 목적함수를 최대화 == 최대 보상을 받는 경로를 구성하는 것
1.2 심층 강화학습 알고리즘의 종류
정책 기반
$J(\tau) = \mathbb{E}_{\tau \sim \pi}[R(\tau)]$ 최대화하는 $\pi$찾기
- 최적 정책 수렴이 보장
- 분산이 크고 표본 비효율적
ex: Reinforce
가치 기반
\[V^\pi(s)=\mathbb{E}_{s_0=s, \tau \sim \pi}[\sum_{t=0}^{T}\gamma_t r_t]\] \[Q^\pi(s,a)= \mathbb{E}_{s_0=s, a_0=a, \tau \sim \pi}[\sum_{t=0}^{T}\gamma_t r_t]\]- 표본 효율적
- 최적정책 수렴보장 X
ex: Sarsa, Dqn
모델 기반
\(P(s_{t+1}\|s_t,a_t)\) 가 주어지거나, 학습
⇒ 최적 길찾기 문제
- 모델 학습 어려움
- 오차 비약적으로 증가
ex: mcts
- on-policy: 정책에 대해서 학습 → 훈련과정에서 $\pi$로부터 생성된 데이터만을 이용
- off-policy: 모든 데이터로 훈련 ⇒ data efficient
1.3 강화학습과 지도학습의 차이
- 오라클의 부재: 정확한 목표값을 모름
- 피드백의 희소성: 대부분 상태의 보상이 0에 수렴함
- 에이전트와 환경이 상호작용하여 데이터 생성: 오차가 커짐
2. Reinforce
이름에서 알 수 있듯이 좋은 결과를 초래했던 행동을 강화(더 높은 확률로 선택되도록)하는 것이다.
⇒ \(J(\pi_\theta) = \mathbb{E}_{\tau \sim \pi_\theta}[R(\tau)] = \mathbb{E} _{\tau \sim \pi_\theta}[\sum_{t=0}^{T}\gamma ^t r_t]\)를 최대화
⇒ \(\theta \leftarrow \theta + \alpha \nabla_\theta J(\pi_\theta)\), \(\nabla_\theta J(\pi_\theta) = \mathbb{E}_{\tau \sim \pi_\theta}[\sum_{t=0}^T R_t(\tau)\nabla_\theta \log\pi_\theta(a_t\|s_t)]\)
2.1 정책 경사 계산
\(\nabla_\theta J(\pi_\theta) = \nabla_\theta\mathbb{E}_{\tau \sim \pi_\theta}[R(\tau)] = \mathbb{E}_{\tau \sim \pi_\theta}[\sum_{t=0}^T R_t(\tau)\nabla_\theta \log\pi_\theta(a_t\|s_t)]\)를 유도해보자.
보조정리 1.
\[\nabla_\theta\mathbb{E}_{x \sim p(x\|\theta)}[f(x)] = \mathbb{E}_{x \sim p(x\|\theta)}[f(x)\nabla_\theta\log p(x\|\theta)]\]보조정리 2.
\[\log p(\tau \|\theta) = \sum_{t\geq0}(\log p(s_{t+1}\|s_t,a_t) + \log \pi_\theta(a_t\|s_t))\]보조정리 1에 의해, \(\nabla_\theta\mathbb{E}_{\tau \sim \pi_\theta}[R(\tau)] = \mathbb{E}_{\tau \sim \pi_\theta}[R(\tau)\nabla_\theta\log p(\tau \|\theta)]\)가 성립하고, 보조정리 2에 의해, \(\mathbb{E}_{\tau \sim \pi_\theta}[R(\tau)\nabla_\theta\log p(\tau \|\theta)] = \mathbb{E}_{\tau\sim\pi_\theta}[\sum_{t=0}^TR(\tau)\nabla_\theta\log\pi_\theta(a_t \|s_t)]\)가 성립한다. 한편, $a_t$를 선택하는 행위는 시간 $t$ 이후로만 영향을 끼치며, 몬테카를로 법칙에 따라 다음이 성립하게 된다.
\[\nabla_\theta J(\pi_\theta) = \nabla_\theta\mathbb{E}_{\tau \sim \pi_\theta}[R(\tau)] \approx \sum_{t=0}^T R_t(\tau)\nabla_\theta \log\pi_\theta(a_t|s_t)\]2.2 알고리즘 구현
- 한 에피소드를 진행하고, 데이터를 모은다.
- $R_t(\tau)$를 recursive하게 계산한다.
- 이를 활용하여 $\nabla_\theta J(\pi_\theta)$를 계산하고, 파라미터를 업데이트 한다.
중요 포인트
- $R_t(\tau)$를 계산할 때, 종료시점 부터 역순으로 recursive하게 계산하면 $t$시간만에 계산이 가능하다.
$R_t(\tau)$에 특정 기준 값을 빼줌으로서 더 유용한 분포를 만들 수 있다.
보상값이 대부분 음인 경우 유용
3. SARSA
3.1 Q함수와 V함수
\[V^\pi(s)=\mathbb{E}_{s_0=s, \tau \sim \pi}[\sum_{t=0}^{T}\gamma_t r_t]\] \[Q^\pi(s,a)= \mathbb{E}_{s_0=s, a_0=a, \tau \sim \pi}[\sum_{t=0}^{T}\gamma_t r_t]\]Q함수는 에이전트에게 행동할 수 있는 직접적인 방법을 제공해 준다.
Q함수를 통해 에이전트는 상태 s에 대해 최대의 Q값을 갖는 a를 바로 선택할 수 있다.
반면 V함수는, s에서 선택 가능한 모든 a를 통해 다음 상태 s’들의 V값을 계산해서 행동해야 한다.
그러나 이는 비용이 크고, 전이함수를 모르면 쉽지 않다.
Q함수는 계산하기 더 복잡하고, 학습하기 위해 더 많은 데이터가 필요하다.
상태 s에서 나온 데이터는 상태 s의 V함수에 모두 활용될 수 있지만, Q함수에는 일치하는 행동에만 활용이 된다.
3.2 시간차 학습
Reinforce에서 사용된 것과 같은 몬테카를로 알고리즘은, 한 에피소드가 끝날 때까지 기다린 후 학습할 수 있다는 단점이 있다.
이를 해결하기 위해, SARSA에서는 TD학습을 활용한다. 벨만 방정식에 따라, Q함수를 recursive하게 정의할 수 있다.
\[Q^\pi(s,a)=\mathbb{E}_{s'\sim p(s' \|s,a), \ \ r\sim R(s,a,s')}[r+\gamma\mathbb{E}_{a'\sim \pi(s')}[Q^\pi(s',a')]]\]이를 TD 학습을 적용하면, Q함수에 대한 추정값으로 바꿀 수 있다.
$Q^\pi(s,a)\approx r+\gamma Q^\pi(s’,a’)=Q_{tar}^\pi(s,a)$ 즉 현재 계산한 Q함수를 target Q함수에 가깝게 업데이트 하는 것이다. 지도학습과 유사하다.
위 식의 의미는, 한 단계 미래의 상태를 봄을 통해, 미래에서 일어난 사건을 점진적으로 현재까지 반영하여 Q함수를 계산하게 된다는 것이다.
이는 에이전트의 특적 목적은, 궤적이 진행됨에 따라 드러난다는 점에서 가치가 있다.
한편, target Q함수에서 두 번의 기댓값을 생략했다. 바깥쪽 기댓값은 궤적을 충분히 많이 가짐으로서 해결할 수 있다.
안쪽의 기댓값은 해결하는 방식에 따라 SARSA와 DQN으로 구분할 수 있다.
- SARSA: 실제로 다음 상태에서 취해진 행동으로 근사
- DQN: 가장 큰 Q함수 값을 갖는 행동으로 근사
또한 식의 파라미터 $\gamma$에 대해 생각해볼 필요가 있다. $\gamma$가 작으면, 에이전트는 근시안적이 되고 바로 일어날 보상에 대해서만 관심을 갖게 된다. 반면, $\gamma$가 크면, 에이전트는 목표 상태에 도달하는 속도에 큰 관심을 갖지 않게 될 것이다. 또한, $\gamma$이 작으면, Q함수의 학습속도는 빠르지만, 에이전트의 성능은 저하될 수 있다. 반대로 $\gamma$가 크면, 학습속도는 느리지만, 학습결과는 더 우수해진다.
3.3 탐험과 활용
local minimum에 빠지지 않도록, 탐험과 활용의 비율을 적절히 조절해야한다. 왜냐하면, 탐욕만을 추구할 경우, Q함수의 편향은 실제 행동의 편향으로 이어질 것이기 때문이다.
따라서, SARSA에서는 $\epsilon$-greedy policy를 사용한다.
3.4 알고리즘 구현
- 현재 상태 $s$, 현재 행동 $a$를 통해 그다음 상태 $s’$를 도출한다.
- $\epsilon$-greedy policy를 활용하여 $a’$를 찾는다.
- target Q함수와 Q함수의 오차를 활용하여 파라미터를 업데이트 한다.
- $s \leftarrow s’$, $a \leftarrow a’$로 업데이트 하고, 이를 반복한다.
중요 포인트
SARSA는 on-policy 알고리즘이므로 특정 정책에서 얻은 경험은 그 정책을 개선하는데만 사용될 수 있다.
target Q값은 현재의 정책으로 인해 greedy하게 선택된 행동을 통해 계산하였기 때문이다.
Reinforce와 달리 시간차 알고리즘을 통해 일정량의 데이터(배치)를 모은 후 train을 할 수 있다. → batch training(←→episodic training)
4. DQN
4.1 DQN의 Q함수 학습
$Q_{tar:SARSA}^\pi(s,a) = r+\gamma Q^\pi(s’,a’)$
$Q_{tar:DQN}^\pi(s,a) = r+\gamma \max_{a’}Q^\pi(s’,a’)$
SARSA와 DQN의 타깃 Q함수는 위와 같은 차이가 있다. 다음 상태 s’에서 정책에 따라 실제 취해진 행동 a’에 대해 계산하지 않고, DQN은 선택가능한 모든 a’에 대한 Q함수중 가장 최대인 a’에 대해 계산한다.
즉 DQN은 데이터가 샘플링된 정책과 상관없이, 특정 s’에 대해 같은 Q함수 값을 도출한다. 이를 통해 DQN은 경험과 정책의 상관성에서 벗어날 수 있다.
또한 Q함수에 max를 취해준다는 것은, (s’,a’)에 대한 Q함수의 추정값이 정확하다는 가정 아래, Q함수를 최대화하는 행동을 선택하는 것이다. 이것이 에이전트가 할 수 있는 최선이다.
4.2 DQN의 행동 선택
DQN이 off-policy 알고리즘이지만, 여전히 경험을 수집하는 방식은 중요한 문제이다. 상태-행동 공간이 아주 클 경우, naive DQN은 모든 상태를 경험하기 힘들 것이다.
이는 Q함수를 신경망으로 근사함으로서 어느 정도는 해결 될 수 있지만, 불연속적인 보상에 대해서는 예측이 어려움 등 여전히 한계가 존재한다.
따라서, DQN에서도 SARSA처럼 $\epsilon$-greedy policy를 사용하거나, 볼츠만 정책을 활용함을 통해 문제를 해결할 수 있다.
볼츠만 정책
볼츠만 정책은 행동의 상대적인 Q가치를 이용하여 행동을 확률적으로 선택한다.
\[p_{softmax}(a \|s)=\frac{e^{Q^\pi(s,a)}}{\sum_{a'}e^{Q^\pi(s,a')}}\] \[p_{boltzman}(a \|s)=\frac{e^{Q^\pi(s,a)/\tau}}{\sum_{a'}e^{Q^\pi(s,a')/\tau}}\]$\tau$를 크게 하면, 분포는 더 균일해지고, $\tau$를 작게하면 분포는 더 집중된 분포를 가진다.
$\epsilon$-greedy policy에 비교했을 때의 장점은, 환경을 덜 무작이로 탐험한다는 것이다. $\epsilon$의 확률로 무작위로 선택하는 것이 아닌, Q가치에 비례하여 무작위로 행동을 선택한다.
따라서 볼츠만 정책은 $\epsilon$-greedy policy보다 Q가치 추정값과 행동 확률 사이의 관계를 더 부드럽게 만든다.
다만 Q가치 추정값이 최적 Q가치와 오차가 큰 경우, $\epsilon$-greedy policy가 더 유리하다. 이를 해결하기 위해 훈련 초기에 $\tau$를 키울 수 있다.
4.3 경험 재현
On-policy 알고리즘은
- 업데이트를 위해 오직 현재 정책에 따라 수집된 데이터만을 이용할 수 있다. 따라서 타깃 Q함수와 기존 Q함수의 차이가 큰 경우와 같이 한 경험으로 여러번의 파라미터 업데이트가 필요한 문제를 해결하지 못한다.
- 수집된 데이터들은 한 정책으로부터 나온 것이므로 서로 밀접하게 연관되어있다. 이로 인해 파라미터 업데이트의 분산이 커질 수 있다.
반면 Off-policy 알고리즘은
- 한번 사용된 경험을 폐기할 필요가 없다. ⇒ experience replay(경험 재현)
- 경험들의 연관성이 낮아진다.
4.4 알고리즘 구현
- 에피소드를 최소량의 경험 데이터가 모일때까지 진행한다.
- 이후 주기적으로, 경험 데이터를 통해 파라미터를 업데이트 한다.
중요 포인트
- expierence replay를 통해 batch방식으로 파라미터를 업데이트할 수 있다.
5. 향상된 DQN
5.1 목표 네트워크
DQN은 TD학습을 이용한다. 즉, 현재 Q함수를 타깃 Q함수의 방향으로 파라미터를 업데이트 한다.
여기서 중요한 점은, 두 Q함수를 근사하는데 활용된 파라미터가 동일하다는 점이다.
이로 인해 발생하는 문제점은, 업데이트의 목표도 계속 함께 움직인다는 것이다.
이를 해결하기 위해, 타깃 Q함수를 위한 별도의 네트워크를 구성하고, 이 목표 네트워크를 주기적으로 메인 네트워크로 업데이트 한다.
이를 통해 일반적인 지도 회귀 문제로 전환할 수 있다.
이를 치환 업데이트 라고 부르며, 이와 다르게 폴리악(polyak) 업데이트를 시행할 수도 있다.
목표 네트워크의 추가로 인해 훈련속도가 저하될 수 있다는 단점이 있다. 이는 업데이트 주기를 조절함을 통해 해결할 수 있다.
5.2 이중 DQN
DQN은 타깃 함수를 추정할 때, 추정값의 최댓값을 활용한다. 그러나, 타깃함수에 오차가 조금이라도 있다면, 최댓값이 양의 방향으로 편향되어 과대 추정이 일어나게 된다.
$Q_{tar:DQN}^\pi(s,a) = r+\gamma \max_{a’}Q^\pi(s’,a’)$에서 max를 취함으로서 발생하는 문제이다.
이것은 최대 기댓값 과대 추정이라는 문제인데, $s’$에서 취할 수 있는 $a’$가 많을 수록, 더욱 크게 편향된다.
한편, DQN은 자주 경험한 쌍에 대해 더 자주 과대 추정을 하게 되고, 에이전트가 균일하게 탐험하지 못했을 경우, 이는 악순환을 만든다.
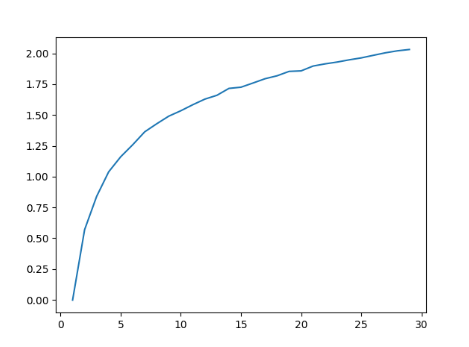
아래 코드와 그래프로 최대 기댓값 추정 문제를 시뮬레이션 해볼 수 있다. 비록 정확한 기댓값을 계산하지는 않았지만(아래에서는 mean으로 계산), 결과와 의미 자체는 동일하다.
1
2
3
4
5
6
7
8
9
10
11
12
13
import numpy as np
import matplotlib.pyplot as plt
def maxexpred(n_act):
s = []
for i in range(10000):
s.append(max(np.random.normal(0, 1, n_act)))
return np.mean(s)
x = range(1, 30)
y = [maxexpred(i) for i in x]
plt.plot(x, y)
plt.savefig('img.png')
아무튼 이러한 문제점을 해결하는 방법은, 다음과 같이 네트워크를 하나 추가하는 것이다.
$Q_{tar:DoubleDQN}^\pi(s,a) = r + \gamma Q^{\pi_\varphi}(s’,\max_{a’}Q^{\pi_\theta}(s’,a’))$
그리고 이를 구현할 시에는, 위에서 살펴본 목표 네트워크로 두 가지 역할을 모두 수행하면 된다.
5.3 우선순위가 있는 경험 재현(PER)
직관적으로, 새로운 작업을 할 때, 어떤 경험이 다른 것보다 더 많은 것을 알려주는 상황을 생각해볼 수 있다.
DQN에서는 TD오차가 큰 경우가 해당될 것이다. 이러한 관점에서, 경험을 기억에서 무작위로 추출하기 보다는, 경험에 우선순위를 부여해서 추출하자는 개념이다.
\(P(i) = \frac{(\|w_i \| +\epsilon)^\eta}{\sum_j(\| w_j \| +\epsilon)^\eta}\), $w_i$는 i번째 경험에 대한 TD오차, $\eta$가 클 수록 우선순위를 강하게 부여
한편, 이와 같은 방식으로 경험의 분포에 대한 기댓값이 바뀌게 되고, 편차가 생기게 된다. 이를 해결하기 위해 TD오차에 가중치를 곱함으로써 보정할 수 있다.
이 방법을 importance sampling이라고 한다.
5.4 알고리즘 구현
중요 포인트
- 네트워크를 하나 추가함을 통해, target network와 double DQN을 동시에 구현할 수 있다.
- PER을 구현할 때, 파라미터를 업데이트 할 때마다 경험들에 대한 TD오차를 다시 계산해야 한다.
- Sum Tree를 사용하면, PER을 효율적으로 구현할 수 있다.
6. A2C
학습된 강화 신호가 환경에서 얻는 보상보다 정책에 대해 더 많은 것을 알려줄 수 있다.
6.1 행동자
행동자는 정책 경사를 이용하여 정책 $\pi_\theta$를 학
습한다.
- A2C: \(\nabla _\theta J(\pi_\theta) = \mathbb{E}_t[A_t^\pi\nabla_\theta \log\pi_\theta(a_t \|s_t)]\)
- Reinforce: \(\nabla _\theta J(\pi_\theta) = \mathbb{E}_t[R_t(\tau)\nabla_\theta \log\pi_\theta(a_t \|s_t)]\)
6.2 비평자
비평자는 (s,a)쌍을 평가하는 방법을 학습하고, 그 결과를 이용하여 $A^\pi$를 생성한다.
어드밴티지 함수
어드밴티지 함수: $A^\pi(s_t,a_t)=Q^\pi(s_t,a_t)-V^\pi(s_t)$
강화 신호의 품질이 우수하다.
상태 s에서 모든 행동을 고려하여 특정 행동 a를 평가하며 행동 a의 상대적 우수성을 강화 신호로 만든다.
강화 신호가 상대적이지 않다면, $Q^\pi(s_t,a_t) >0$ 이고 $A^\pi(s_t,a_t)<0$인 경우 문제가 생기게 된다.
행동의 장기적 효과를 포착한다.
어드밴티지는 정책이 현재 특별히 좋지 않은 상태에 있다고 해서 행동을 억제 하지 않는다.
반대로, 좋은 상태에 있는 정책에 대해 행동에 가점을 주지 않는다.
이를 통해 행동이 미래의 가치를 어떻게 변화시킬지만을 고려하여 행동을 평가하게 된다.
어드밴티지를 추정하는 방법은 크게 두 가지가 있다.
두 방법 모두 V함수를 먼저 학습하고, V를 통해 Q를 계산한다.
이유는, Q함수가 V함수에 비해 더 복잡하고 더 많은 표본을 필요로 하며, Q로부터 V를 추정하는 것이 더 많은 계산을 필요로 하기 때문이다.
1. n단계 이득(n-step forward return)
n단계 이득에서 학습된 V로 Q를 추정하는 방법은 아래와 같다.
\[Q^\pi(s_t,a_t)=\mathbb{E}_{\tau\sim\pi}[r_t+\gamma r_{t+1} + \cdot\cdot\cdot+\gamma^nr_{t+n}]+\gamma^{n+1}V^\pi(s_{t+n+1})\] \[\approx r_t +\gamma r_{t+1} + \cdot\cdot\cdot+\gamma^n r_{t+n} + \gamma^{n+1}\hat{V}^\pi(s_{t+n+1})\]등호는 보상의 합의 기댓값과 완벽한 V함수를 알고 있을 때 성립한다.
이를 계산 가능하도록, 기댓값 대신, 보상의 궤적을 사용하고, 비평자가 학습한 V함수를 사용한다.
n을 키우면 편향은 줄어들지만 분산은 커지고, n을 줄이면 분산은 줄어들지만 편향은 커진다.
$A^\pi_{NSTEP}(s_t,a_t)=Q^\pi(s_t,a_t)-V^\pi(s_t)$
\[\approx r_t +\gamma r_{t+1} + \cdot\cdot\cdot+\gamma^n r_{t+n} + \gamma^{n+1}\hat{V}^\pi(s_{t+n+1}) - \hat{V}^\pi(s_t)\]2. 일반화된 어드밴티지 추정(GAE)
이 방법은 하나의 n값을 선택하는 문제를 해결하기 위해, 여러개의 n값을 이용한다.
이를 위해, n단계 어드밴티지 추정기를 다음과 같이 정의한다.
$A_t^\pi(n) = r_t + \gamma r_{t+1} + \cdot\cdot\cdot + \gamma^nV^\pi(s_{t+n})-V^\pi(s_t)$
그리고 GAE는 다음과 같이 어드밴티지 추정기의 지수가중평균으로 계산된다.
$A_{GAE}^\pi(s_t,a_t)=(1-\lambda)(A_t^\pi(1) + \lambda A_t^\pi(2) + \cdot\cdot\cdot)$
$\delta_t = r_t+\gamma V^\pi(s_{t+1})-V^\pi(s_t)$를 활용하면, 아래와 같은 공식으로 정리할 수 있다.
\[\begin{align} & A^{\pi}_t(1) = \delta_t & &= r_t + \gamma V(s_{t+1}) - V(s_t) \\& A^{\pi}_t(2) = \delta_t + \gamma \delta_{t+1} & &= r_t + \gamma r_{t+1} + \gamma^2 V(s_{t+2}) - V(s_t) \\& A^{\pi}_t(3) = \delta_t + \gamma \delta_{t+1} + \gamma ^2 \delta_{t+2} & &= r_t + \gamma r_{t+1} + \gamma^2 r_{t+2} + \gamma^3 V(s_{t+3}) - V(s_t)\end{align}\] \[\begin{align}A_{GAE}^{\pi}(s_t,a_t) &= (1-\lambda)\Big(A_{t}^{\pi}(1) + \lambda A_{t}^{\pi}(2) + \lambda^2 A_{t}^{\pi}(3) + \cdots \Big) \\&= (1-\lambda)\Big(\delta_t + \lambda(\delta_t + \gamma \delta_{t+1}) + \lambda^2(\delta_t + \gamma \delta_{t+1} + \gamma^2 \delta_{t+2})+ \cdots \Big) \\&= (1-\lambda)\Big( \delta_t(1+\lambda+\lambda^2+\cdots) + \gamma\delta_{t+1}(\lambda+\lambda^2+\cdots) + \cdots \Big) \\&= (1-\lambda)\left(\delta_t \frac{1}{1-\lambda} + \gamma \delta_{t+1}\frac{\lambda}{1-\lambda} + \cdots\right) \\&= \sum_{l=0}^\infty (\gamma \lambda)^l \delta_{t+l}\end{align}\]3. 어드밴티지 함수에 대한 학습
n단계 이득과 일반화된 어드밴티지 추정 모두, V함수에 대한 학습을 필요로 한다. 이는 DQN에서 했던것 과 같이 TD학습을 통해 타깃 함수와의 오차를 이용해 학습된다.
그리고 계산을 간단히 하기 위해, 각 알고리즘에서 어드밴티지 함수를 구성하는 방식을 활용해서 타깃함수를 만든다.
n-step: $V_{tar}^\pi(s_t)=r_t+\gamma r_{t+1} + \cdot\cdot\cdot + \gamma^n r_{t+n} + \gamma r^{r+1}\hat{V}^\pi(s_{t+n+1})$
GAE: $V_{tar}^\pi(s_t)=A^\pi_{GAE}(s_t,a_t)+\hat{V}^\pi(s_t)$
6.3 알고리즘 구현
- 한 에피소드를 진행하고, 데이터를 모은다.
- 비평자 네트워크를 통해, V함수의 예측값을 계산한다.
- V함수의 예측값을 활용하여 어드밴티지 함수를 계산한다.
- 어드밴티지 함수를 활용하여 타깃함수를 만든다.
- 행동자 네트워크를 활용하여 엔트로피를 계산한다.
- 비평자 네트워크의 손실값을 계산한다.
- 행동자 네트워크의 손실값을 계산한다.
- 파라미터를 업데이트한다.
중요 포인트
- n-step이냐 GAE냐에 따라서 타깃함수를 만드는 법이 달라진다.
- 엔트로피값을 행동자 네트워크의 손실값에 빼줌을 통해 정책의 분포의 균일함을 유지할 수 있다.
- 비평자와 행동자 네트워크를 한개의 네트워크로 구성할 수 있다. 스칼라 가중치를 이용해 균형을 맞출 필요가 있다.
7. PPO
7.1 성능 붕괴
성능 붕괴 문제란 정책 경사 알고리즘(Policy Gradient)에서 발생하는 문제이다. 파라미터 업데이트를 위한 이상적인 학습률을 결정하기 어렵기 때문에 발생한다.
적절하지 않은 학습률 $\alpha$는 local maxima에 빠트리거나, 좋은 정책을 건너뛰게 만들어 성능 붕괴를 일으킨다.
학습률을 결정하기 어려운 결정적인 원인은, 정책공간과 파라미터 공간이 정확하게 대응되지 않는다는 데 있다.
즉, \(d_\theta(\theta_1,\theta_2)=d_\theta(\theta_2,\theta_3)\nLeftrightarrow d_\pi(\pi_{\theta_1},\pi_{\theta_2})=d_\pi(\pi_{\theta_2},\pi_{\theta_3})\)라는 것이다.
이를 해결하기 위해, 파라미터로 업데이트로 새로 만든 정책의 상대적인 성능을 측정하는 방법이 필요하다.
7.2 TRPO
상대적 성능 식별자는 두 정책의 목적 함수 사이의 차이로 정의할 수 있다. 그리고 아래 식을 통해 계산 가능하다.
\[J(\pi')-J(\pi)=\mathbb{E}_{\tau \sim \pi'}[\sum_{t=0}^T\gamma^tA^\pi(s_t,a_t)]\]증명은 아래와 같다.
\[\mathbb{E}_{\tau\sim\pi'}[\sum_{t=0}^T\gamma^tA^\pi(s_t,a_t)] = \mathbb{E}_{\tau\sim\pi'}[\sum_{t\ge0}\gamma^t(\mathbb{E}_{s_{t+1},r_t\sim p(s_{t+1},r_t|s_t,a_t)}[r_t+\gamma V^\pi(s_{t+1})] - V^\pi(s_t))]\]어드밴티지 함수를 전개한다.
\[=\mathbb{E}_{\tau\sim\pi'}[\sum_{t\ge0}\gamma^t(r_t+\gamma V^\pi(s_{t+1})-V^\pi(s_t))] = \mathbb{E}_{\tau\sim\pi'}[\sum_{t\ge0}\gamma^tr_t] +\mathbb{E}_{\tau\sim\pi'}[\sum_{t\ge0}\gamma^{t+1} V^\pi(s_{t+1})-\sum_{t\ge0}\gamma^t V^\pi(s_t))]\]내부의 기댓값이 사라지는 이유는, 바깥쪽의 기댓값은 전이함수로부터 나온 상태와 보상의 기댓값을 포함하기 때문이다. 또한 기댓값의 선형성을 활용하였다.
\[=J(\pi')+\mathbb{E}_{\tau\sim\pi'}[\sum_{t\ge1}\gamma^{t} V^\pi(s_{t})-\sum_{t\ge0}\gamma^t V^\pi(s_t))]=J(\pi')-\mathbb{E}_{\tau\sim\pi'}[V^\pi(s_0)]\]식을 단순히 변형하였다.
\[=J(\pi')-\mathbb{E}_{\tau\sim\pi'}[J(\pi)]=J(\pi')-J(\pi)\]증명 끝.
한편, \(J(\pi')-J(\pi)=\mathbb{E}_{\tau \sim \pi'}[\sum_{t=0}^T\gamma^tA^\pi(s_t,a_t)]\) 이 식에는 문제점이 있다.
업데이트 이전에 새로운 정책으로 부터 추출된 궤적으로부터 기댓값을 계산해야한다는 것이다. 하지만 새로운 정책은 업데이트 이전에 얻을 수 없다.
이를 해결하기 위해, 중요도 표본추출(importance sampling)을 통해 식을 변형한다.
\[J(\pi')-J(\pi)=\mathbb{E}_{\tau\sim\pi'}[\sum_{t=0}^T\gamma^tA^\pi(s_t,a_t)]\approx\mathbb{E}_{\tau\sim\pi}[\sum_{t\ge0}A^\pi(s_t,a_t)\frac{\pi'(a_t \|s_t)}{\pi(a_t \|s_t)}]=J_\pi^{CPI}(\pi')\]그리고 이를 대리목적(surrogate objective)라고 부른다. 이 새로운 목적함수를 이용한 최적화가 여전히 정책 경사상승을 수행하는지 확인할 필요가 있을 것이다.
\[\nabla_\theta J_{\theta_{old}}^{CPI}(\theta)|_{\theta_{old}}=\nabla_\theta\mathbb{E}_{\tau\sim\pi_{\theta_{old}}}[\sum_{t\ge0}A^{\pi_{\theta_{old}}}](s_t,a_t)\frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{old}}(a_t,s_t)}]|_{\theta_{old}}\] \[=\mathbb{E}_{\tau\sim\pi_{\theta_{old}}}[\sum_{t\ge0}A^{\pi_{\theta_{old}}}(s_t,a_t)\frac{\nabla_\theta\pi_\theta(a_t|s_t)|_{\theta_{old}}}{\pi_\theta(a_t,s_t)|_{\theta_{old}}}]=\mathbb{E}_{\tau\sim\pi_{\theta_{old}}}[\sum_{t\ge0}A^{\pi_{\theta_{old}}}](s_t,a_t)\nabla_\theta\log\pi_\theta(a_t,s_t)|_{\theta_{old}}]\]로그 미분법을 활용한다.
\[=\nabla_\theta J(\pi_\theta)|_{\theta_{old}}\Rrightarrow \nabla_\theta J_{\theta_{old}}^{CPI}(\theta)|_{\theta_{old}}=\nabla_\theta J(\pi_\theta)|_{\theta_{old}}\]이를 통해 대리목적을 최적화하는 것이 곧 정책 향상을 최대화하는 것이라는 것을 알게 되었다. 또한, $J_\pi^{CPI}(\pi’)$가 $J(\pi’)-J(\pi)$에 대한 선형근사라는 것도 알 수 있다.
따라서, $J_\pi^{CPI}(\pi’)$를 활용하기 위해선, $J(\pi’)-J(\pi)\ge0$이 보장되어야 한다. 이는 KL Divergence를 통해 보장할 수 있다.
\[|(J(\pi')-J(\pi))-J_\pi^{CPI}(\pi')| \le C\sqrt{\mathbb{E}_t[KL(\pi'(a_t|s_t)||\pi(a_t|s_t)]}\]이 식은 새로운목적함수 $J(\pi’)$와 추정값 $J(\pi) + J_\pi^{CPI}(\pi’)$의 차이에 대한 절댓값 오차를 표현하다. 그리고 이는 KL Divergence를 통해 제한된다.
이것을 활용하면, 원하는 결과를 유도할 수 있다.
\[J(\pi')-J(\pi) \ge J_\pi^{CPI}(\pi')-C\sqrt{\mathbb{E}_t[KL(\pi'(a_t|s_t)||\pi(a_t|s_t)]}\]즉 정책 변화가 의미 있으려면 정책 향상의 추정값이 KL Divergence보다 커야한다. 그렇지 않은 경우 업데이트를 수행하지 않으면 단조 향상이 보장된다.
최종적으로, 최적화 문제는 다음으로 전환된다.
\[argmax_{\pi'}(J_\pi^{CPI}(\pi')-C\sqrt{\mathbb{E}_t[KL(\pi'(a_t|s_t)||\pi(a_t|s_t)]})\]구현 가능성을 위해, 식을 아래와 같이 바꿀 수도 있다.
\[max_\theta\mathbb{E}_t[\frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{old}}(a_t,s_t)}A_t^{\pi_{\theta_{old}}}] \ \ \ st.\ \mathbb{E}_t[KL(\pi'(a_t|s_t)||\pi(a_t|s_t)] \le \delta\]여기서 $\delta$를 신뢰 영역(trust region)이라고 부르고, 이는 튜닝이 필요한 하이퍼파라미터이다.
7.3 PPO
TRPO의 문제점은 계산량이 많고, $\delta$를 선택해야한다는 것이다. PPO는 두 가지 방식으로 이를 해결한다.
우선, \(r_t(\theta)=\frac{\pi_\theta(a_t \|s_t)}{\pi_{\theta_{old}}(a_t,s_t)}\)를 활용하여, 대리목적을 간단히 표현한다. \(J^{CPI}(\theta)=\mathbb{E}_t[r_t(\theta)A_t]\)
1. 적응 KL 페널티
\[J^{KLPEN}(\theta)=max_\theta\mathbb{E}_t[r_t(\theta)A_t - \beta KL(\pi_\theta(a_t \|s_t)\|\|\pi_{\theta_{old}}(a_t \|s_t)\]이 식은 KL 페널티 대리목적(KL-penalized surrogate objective)이라고 부른다. 이는 PPO에서 $\delta$로 제한조건을 둔 것과 같은 기능을 한다.
$\beta$가 커지면 두 정책 사이의 거리 유지가 강조되고, 작아지면 허용 오차가 높아진다.
한편, 이 식에서도 여전히 적절한 $\beta$를 찾는 문제가 발생한다. PPO에서는 $\beta$가 시간에 따라 다르게 적응하는 것을 제안한다.
즉 $\delta$가 기준보다 작으면 $\beta$를 낮추고, $\delta$가 기준보다 크면 $\beta$를 키운다. 하지만 여전히 기준 $\delta$값 선택 문제를 해결하지 못한다….
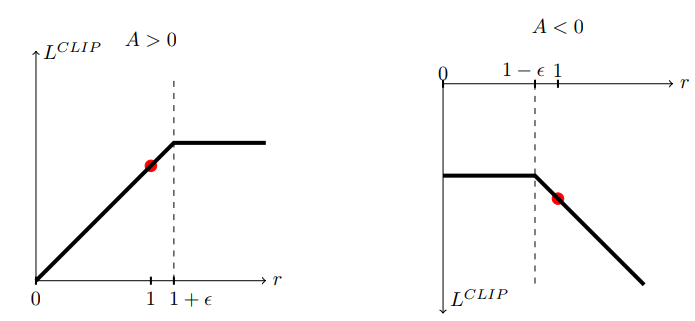
2. 대리목적 클리핑
$J^{CLIP}(\theta)=\mathbb{E}_t[min(r_t(\theta)A_t, \ clip(r_t(\theta), 1-\epsilon,1+\epsilon)A_t)]$
이를 클리핑이 적용된 대리목적(clipped surrogate objective)라고 부른다.
클리핑을 적용함을 통해, $r_t(\theta)$를 $[1-\epsilon, 1+\epsilon]$의 범위 밖으로 벗어나게 만들 정도로 정책을 변화시킬 이유가 없다.